Neural networks are the backbone of many classification problems, which deals with the perceptual data involved in images, video, and audio. One such classification problem is to determine the identity of a speaker(Customer/User and Agent Representative) from an audio sample of their voice.
Number of voice bio-metric systems have been developed in the industry which can extract speaker information from the recorded voice and identify the speaker from a set of trained speakers and other business required information.

In this post, I will outline the speaker identification system using Simple AWS Lambda function and NLTK libraries, which converts the Conversation files into the extracted and meaningful json data.
This blog post is broken into the following parts:
1. Differentiating the speakers into 3 units
Example:
speaker1(Customer)
speaker2(Agent)
Combined message(Both Customer & Agent)
2. Create a chat log(dialogue-box) from speaker-1 & speaker-2 dialogues
Example:
speaker1: Hi there!
speaker2: Welcome to DataCloudies!
Speech to text output conversation:
To achieve the separating two speakers from speech to text output we are using AWS transcribe with Channel Identification which is a AWS managed service that helps to convert speech to text quickly and accurately. Resultant output file consists of text conversation, two channels (channel 1 and channel 2) indicating the two different speakers with vocabulary formatting on the channel contents. Here is the format of Transcribe output looks,

For the configuration and setup of aws transcribe with Channel Identification suggest you to refer to AWS Transcribe.
Sample output:

The final converted transcribe output file will be the input data for the Lambda function. In this article, we will discuss about the process of differentiating the speakers data.
1. Differentiating the speakers into 3 units
Create a Lambda function in AWS with Python run-time and proceed with the below code.
a. Import necessary libraries

b. Extract the source data(transcribe output data) from S3 bucket and insert into the list

c. As AWS Transcript supports multiple languages (English,German,Spanish etc), write the below module to identify the language.

d. capture start and end time of the conversation

e. Gather the speaker-1 data


f. Gather the speaker-2 data

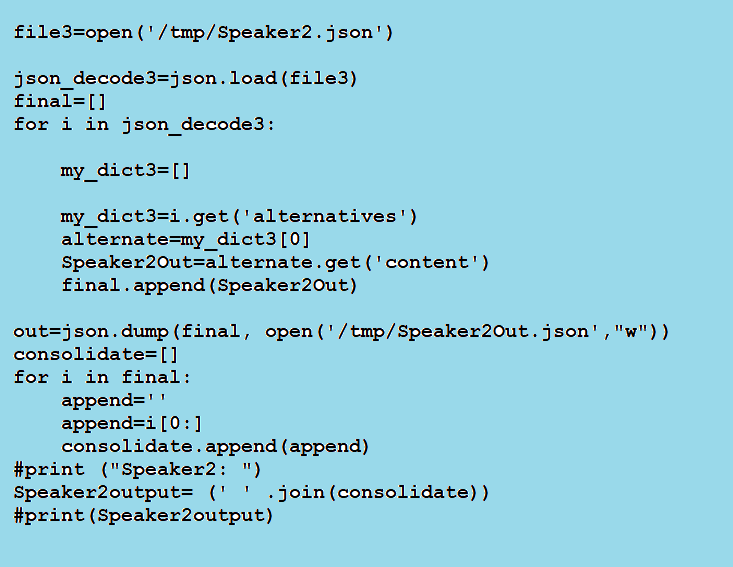
g. Write the below piece of lines to capture the combined message

Final output:

Here it ends, We have successfully transformed the transcribe data into the prescribe format. Please follow the next post for creating the chat log from speakers' conversations. Thank you!